

(「金融社畜の妖精『にほんばっしー』に突撃(4) 驚異の的中率を誇る米雇用統計予想法!」から続く)
■複数の期間でモデル予想値を算出
少し話が脱線しましたが、「にほんばっしーモデル」に話を戻しましょう。「にほんばっしーモデル」ができるまでの第1のポイントは、材料選びということで、詳しく説明していただきましたが、次のポイントは何でしょうか?
「材料選びと同じく大事なのが、過去どのくらい遡って傾向性を探るか、つまり『期間』という観点が大事です」
第2のポイントは、期間ですね。
「ええ。過去31カ月~55カ月分のサンプルを使って、それぞれのモデルがどんな予想値になるのかを算出しています。そして、その予想値が実際の結果とどれだけシンクロしているかをまず見ていくんです」
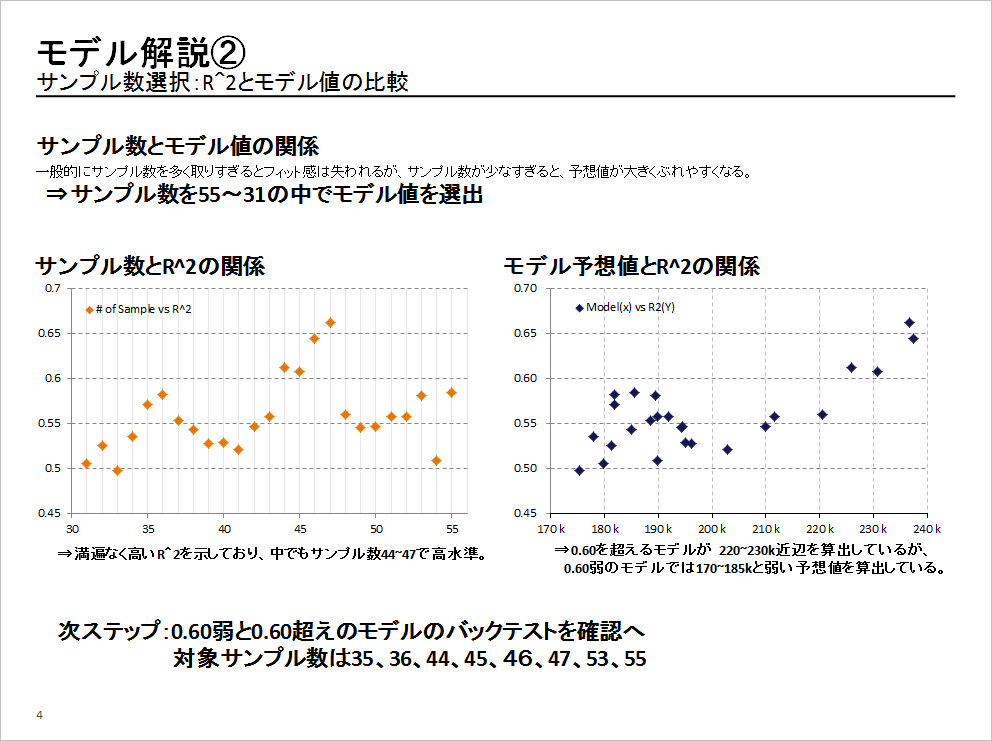
「資料にある『サンプル数』は、過去何カ月間かという期間を表しています。左側の表で見ると横軸です。縦軸は、決定係数というものを表しており、1に近づくほどシンクロ率が高いということです」
ちなみに、右側のグラフには、各モデルが出したNFP(非農業部門雇用者数変化)の予想値と各モデルの決定係数の関係が示されています。
で、5月に発表された4月米雇用統計のNFPを予想するにあたって、Aさんは、サンプル数、35、36、44、45、46、47、53、55カ月を選び、バックテストを実施。モデル予想値を算出しました。
算出した各モデル予想値の中から、米雇用統計のNFPで発表される数値を当てにいくそうなのですが、ここで大事なのは、選んだモデルの予想値の中に正解となる数値が入っているということ、だそうです。

■ヒットレンジに入る確率は、だいたい80%!
「これは、野球でいうと、ヒットレンジみたいなもの。このモデル予想値のなかに正解が入っているかどうかが大事なんです。ここに入っていなければ、そもそも数値を当てることはできませんから。
ヒットレンジに入ってない時は、僕の予想方法そのものが間違っている時。何か突発的な要因があるということなので、当てられません。でも、ヒットレンジの中に入っている時は、最後の選択さえ間違わなければ当てにいけます!
今回もそうです。僕が『にほんばっしーモデル』として選んだモデル予想値はドンピシャではありませんでしたが、正解は、このヒットレンジの中には入っていたんです」
ヒットレンジに入る確率は、どのくらいなんですか?
「過去のものをあわせると、だいたい80%です」
すごーい! 驚異の的中率ですね。
「ありがとうございます。でも、いつもどのモデル予想値を採用するかを決めてからは、ナイーブになりながら、米雇用統計の発表時間(米国夏時間:21時30分)を待っているんですよ(笑)」
■「にほんばっしーモデル」は、一本予想ではなかった!
選んだサンプル数のバックテスト結果を比較すると、以下のとおり。
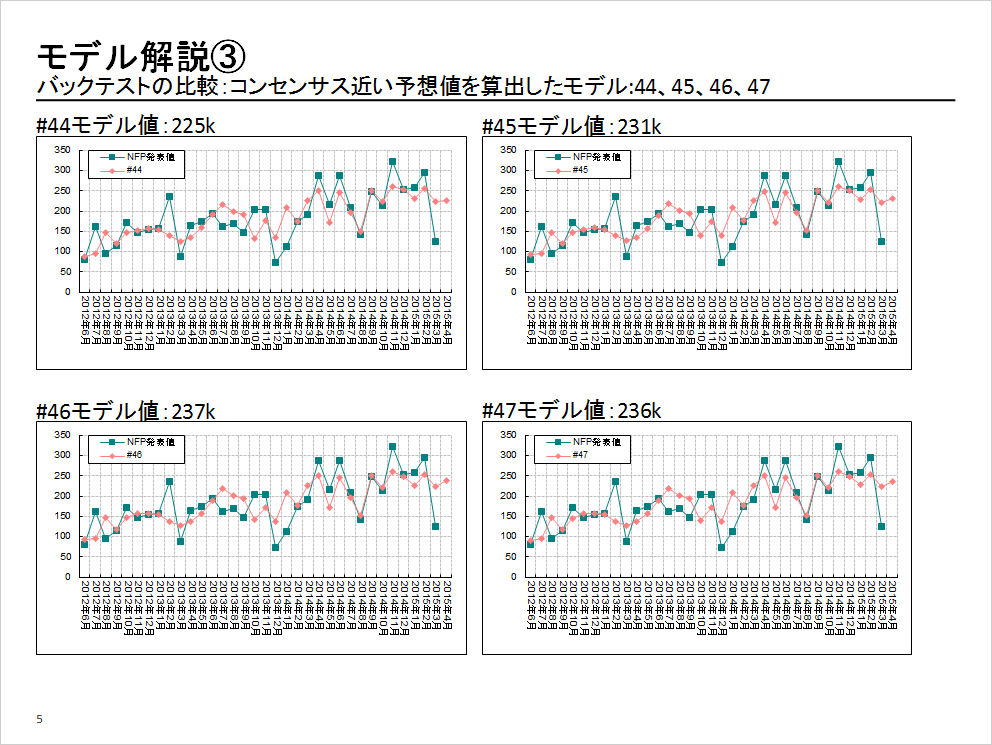
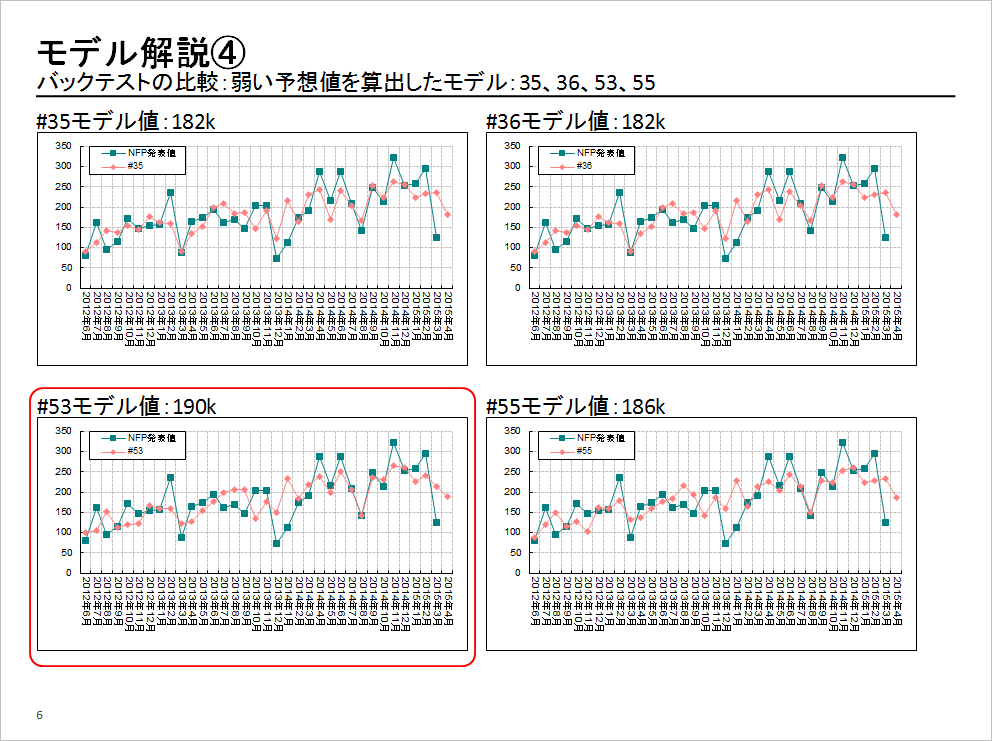
「ピンク色のラインがモデル予想値。青色ラインが実際に発表されたNFPの結果です。今回は、どのモデルが結果を当ててくれるのか? 僕は、53番を選びましたが、結果論で見ると、実際に当たった(結果と一番近い数値になった)のは44番でした」
【4月米雇用統計、NFPの結果】
・ 前回結果:12.6万人(126k)
・ 市場予想:22.8万人(228k)
・ にほんばっしーモデル予想:19.0万人(190k)
・ 結果:22.3万人(223k)
44番のモデル予想値は、22.5万人(225k)、Aさんが選んだ53番のモデル予想値は、19万人(190k)でした。結果は、22.3万人(223k)でしたので、そのほかのモデル予想値を見ても、一番近いのは44番のモデル予想値ですね。
いつも「にほんばっしー」のツイッターで投稿される「にほんばっしーモデル」が1つなので、算出しているモデル予想値も1つなのかなぁなんて思っていましたが、違いました…。
たくさんのモデル予想値の中から、コレというものが「にほんばっしーモデル」として選ばれていたんですね。
■的中するとフォロワーが200人増!? 世界第3位にも!
「『にほんばっしーモデル』が当たると、『にほんばっしー』のツイッターフォロワー数は、一気に200くらい増えるんですよ!」
一気に200もフォロワーが増えるんですか! たしか2015年3月発表のNFPの結果と「にほんばっしーモデル」の数値がすごく近かったですよね? このとき、市場予想の方はだいぶ外れていました。
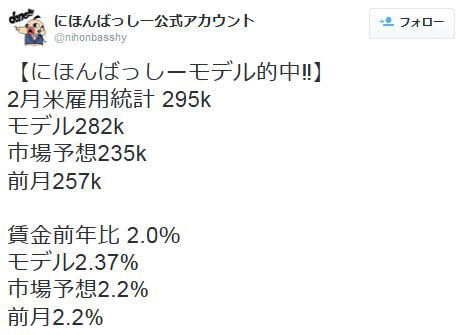
「ええ。そういう時は、一気にフォロワー数が増えます。それにしても、あれは、神がかっていましたね。
ブルームバーグの端末では予想値を入力することができ、自分の予想が世界第何位なのか、ランキングを見ることができるんですが、あの神がかった時は、過去10回分の成績で世界第3位にランクインしました! でも、その後、不振で…しばらくはランキングに戻れなさそうですけどね(笑)」
世界第3位ってすごいですね! ぜひ、早くランキングに戻られることを願っております。
■最後の最後はカンです! 強いて言うならフィット感です!
少し話が戻りますが、最終的に残った複数のモデル予想値の中から、「にほんばっしーモデル」を選ぶ時(数値を当てにいく時)は、何を基準にしているんですか?
「それはもう、カンです!」
カンですか!?
「はい。最後の最後は、カンです。女の子に告白するときも最後は、度胸じゃないですか(笑)でも、強いていうならフィット感ですかね。
単純に、過去の結果とモデル予想値がシンクロしているものを何も考えずに選ぶという方法もあります。僕のように予想値を出す人の中には、そうする人もいると思うんです。ですが、職人技ではないですが、僕は、そのモデル予想値が本当に正しいかどうかを、最後は感覚で判断するんです」
その方が、当たる確率は高いんですか?
「ええ。高いです。結局、コンピューターは合理的な判断はしてくれません。算出したモデル予想値も、実際は、今のマーケットのセンスに合わなかったりするので。
栄養価が高いからといって、青汁がたっぷり入ったカレーをすすめられても、それは食えんだろう! という感じですね(笑)。最後の最後は、その時の『流れ』というものがあるので、それで決めるんです」

まさに職人技ですね。
「そうですね。シンクロ率が同じように高くても、その中には1年前にぴったり予想値が当たっていて、最近は外しているモデルと、昔は外していたけれど、最近は当たっているモデルがあったりするんです。
そのあたりは、コンピューターでは判断してくれません。今回は、どのモデル予想値が当たりそうなのか? やはり最後は、自分の目で見て確認します」
(「金融社畜の妖精『にほんばっしー』に突撃(6)黒田日銀総裁が『追加緩和しないバシ!?』」へつづく)
(取材・文/ザイFX!編集部・向井友代 撮影/和田佳久)











![ヒロセ通商[LION FX]](/mwimgs/9/7/-/img_975127cf2c6be2ac1a68a003ef3669c022946.gif)








株主:株式会社ダイヤモンド社(100%)
加入協会:一般社団法人日本暗号資産ビジネス協会(JCBA)